

Najstarszą z dziedzin naukowych jest astronomia. Przynajmniej od starożytności ludzie zaczęli dostrzegać prawidłowości w ruchach obiektów niebieskich. Następnie nauczyli się konstruować teoretyczne modele, dzięki którym mogli przewidywać takie zjawiska jak zaćmienie Słońca. Wraz z rozwojem matematyki i techniki w XIX w. postęp naukowy dramatycznie przyspieszył. Wydaje się, że dziś stajemy przed nowym wyzwaniem: przeżywamy powódź danych, o której pisze prof. Jarek Gryz >>>
Rewolucja w zbieraniu i przetwarzaniu olbrzymich i różnorodnych zbiorów danych spowodowała, że niektórzy analitycy i publicyści zaczęli głosić „filozofię Big Data”, w myśl której algorytmy całkowicie zastąpią naukowców i ich modele teoretyczne. „Jeśli mamy wystarczająco dużo danych, to liczby mówią same za siebie”, „W erze petabajtów nauka poradzi sobie bez modeli” – pisał w 2008 r. Chris Anderson, redaktor naczelny „Wired”.
To skrajna opinia – inni uważają, że tradycyjna metodologia nauki wymaga pewnego rozszerzenia, ale teoretyków i eksperymentatorów nie trzeba wysyłać na emerytury.
A co o Big Data mówi nam sama matematyka?
Korelacje i przyczyny
Na początek trzeba zadać pytanie, czym właściwie są dane? Z punktu widzenia matematyki to po prostu zestawy (ciągi lub tabele) liczb. Ale oprócz wartości liczbowych dane posiadają także etykiety określające ich znaczenie. Na przykład ciąg liczb: 21, 23, 22, 24, 32, 29, 30 sam w sobie nie wygląda specjalnie ciekawie. Jeśli jednak wiemy, że przedstawia on pomiary temperatury powietrza w Krakowie, natychmiast zauważamy, że pod koniec tygodnia nastąpiło ocieplenie.
Ściślej mówiąc, dane to zbiór wartości pewnych zmiennych losowych. Dopiero w tym kontekście możemy stwierdzić, że pewne wielkości są skorelowane, czyli zmieniają się podobnie (statystyka pozwala zaś mierzyć m.in. siłę korelacji, czyli stopień owego podobieństwa). Na przykład, jeśli ciąg: 17, 19, 19, 18, 25, 27, 26 odpowiada pomiarom temperatury w Zakopanem, to widzimy, że jest on cokolwiek podobny do tego z Krakowa. Ogólnie rzecz biorąc, w górach było chłodniej, ale, podobnie jak i w mieście królewskim, w piątek nastąpiło ocieplenie.
Jeśli jednak przyjmiemy tę korelację za pewnik, to możemy się srogo rozczarować. Bo oto w kolejnym tygodniu zaplanowaliśmy wycieczkę w góry. Zostawiliśmy słoneczny i ciepły Kraków w dobrym humorze, a w Zakopanem przywitał nas rzęsisty deszcz i chłód. Ten przykład pokazuje, że aby uniknąć rozczarowań, musimy nie tylko widzieć korelacje, lecz także rozumieć ich przyczyny.
Zgodnie z zasadą głoszoną przez niemieckiego filozofa Hansa Reichenbacha, jeśli dwa zjawiska są ze sobą skorelowane, to albo jedno jest przyczyną drugiego, albo mają one wspólną przyczynę w przeszłości. Na przykład: ocieplenie w Zakopanem było skorelowane ze wzrostem temperatury w Krakowie ze względu na ciepły front atmosferyczny napływający nad Małopolskę. Z kolei intensywny deszcz w górach może być bezpośrednią przyczyną powodzi w Krakowie.
Margaryna a rozwody
W internecie można jednak znaleźć mnóstwo wykresów ukazujących absurdalne korelacje. Tyler Vigen, autor serwisu i książki „Spurious Correlations”, doszukał się m.in. bardzo silnych korelacji pomiędzy odsetkiem rozwodów w stanie Maine w USA a ilością zjadanej przez Amerykanów margaryny. Znacznie słabiej – ale wciąż zauważalnie – koreluje liczba osób, które utonęły w basenach, z liczbą filmów, w jakich w danym roku zagrał Nicolas Cage (w latach 1999–2009). Potrzeba dużej wyobraźni, żeby doszukać się stojących za tymi korelacjami związków przyczynowo-skutkowych.
Problem przyczyn i korelacji jest jednak poważny, o czym świadczy słynna afera związana z kryzysem ekonomicznym. W 2010 r. dwoje ekonomistów z Uniwersytetu Harvarda, Carmen M. Reinhart i Kenneth S. Rogoff, opublikowało artykuł w czasopiśmie „American Economic Review”. Opierając się na analizie danych, stwierdzili korelację pomiędzy wzrostem gospodarczym danego kraju a stosunkiem jego długu zagranicznego do PKB. Wysnuli z tego wniosek, iż jeśli stosunek długu do PKB jest większy niż 90 proc., to gospodarka rośnie o połowę wolniej. Artykuł ten był cytowany ponad 3 tys. razy, a zawarte w nim tezy zostały przywołane w trakcie ustalania polityki ekonomicznej w USA i Unii Europejskiej w latach 2011-12.
Inni naukowcy zaczęli jednak wskazywać, że korelacja, owszem, istnieje, ale pomylono przyczynę ze skutkiem. Po prostu kraje wolniej rozwijające się mają większy problem z zadłużeniem publicznym. W 2013 r. Thomas Herndon z University of Massachusetts Amherst i współpracownicy wykazali, że korelacja „odkryta” przez naukowców z Uniwersytetu Harvarda jest pozorna, a ich analiza opierała się na nieuzasadnionych założeniach. Reinhart i Rogoff w kolejnych artykułach mocno osłabili swoją kontrowersyjną tezę, ale decyzje ekonomiczne oparte na ich oryginalnych zaleceniach zdążyły już wejść w życie.
Czy my się znamy?
Czy zatem możemy natrafić na korelacje pozbawione sensu, czy też może ich przyczyny zawsze istnieją, ale są głęboko ukryte w gąszczu rozlicznych zjawisk? Nieco światła na to głębokie pytanie rzuca matematyka.
Rozważmy na początek ciąg binarny, czyli składający się z samych zer i jedynek. Możemy zadać pytanie: czy istnieją ciągi binarne całkowicie pozbawione prawidłowości? Okazuje się, że nie! Dobrym przykładem regularności w tym kontekście jest istnienie monochromatycznego podciągu, czyli samych zer lub jedynek pojawiających się w regularnych odstępach wewnątrz naszego binarnego ciągu. Na przykład ciąg 01100110 nie zawiera żadnego podciągu monochromatycznego o długości 3. Natomiast, jeśli dopiszemy na jego końcu 0, to taki podciąg już się pojawi – faktycznie, symbol 0 powtarza się na co czwartej pozycji 011001100. Co ciekawe, jeśli zamiast zera na końcu wpiszemy jedynkę, to taki ciąg również zawiera podciąg monochromatyczny o długości 3. Rzeczywiście, 1 powtarza się na co trzeciej pozycji – 011001101. Okazuje się, że każdy spośród 512 możliwych ciągów binarnych o długości 9 zawiera podciąg arytmetyczny o długości 3. Jest to szczególny przypadek tzw. twierdzenia van der Waerdena.
Można by sądzić, że ten wynik jest jedynie artefaktem zbyt sztywnej struktury ciągów binarnych. Bazy danych to zwykle wielowymiarowe tabele, w których szukamy korelacji pomiędzy kilkuelementowymi zbiorami. Klasycznym, wyżej wymiarowym zagadnieniem jest tzw. problem towarzystwa (ang. party problem). Załóżmy, że na przyjęciu spotyka się sześć osób. Dla każdej pary możemy określić, czy dane osoby się znają, czy też nie. Powstaje pytanie, czy na każdej sześcioosobowej imprezie możemy znaleźć troje ludzi, którzy znają się między sobą, albo którzy są sobie wzajemnie obcy? Odpowiedź jest pozytywna. Można to szybko rozstrzygnąć przy pomocy teorii grafów (zob. ramkę na poprzedniej stronie). Rozwiązanie problemu towarzystwa jest przykładem ogólnego twierdzenia brytyjskiego matematyka, filozofa i ekonomisty Franka Plumptona Ramseya. Korzystając z tego twierdzenia, możemy znaleźć m.in. odpowiedź na pytanie, jak wielka musi być liczba uczestników dowolnego spotkania, by zawsze znalazła się na nim określona grupa znających się lub obcych sobie ludzi (np. jeśli zależy nam na zebraniu czterech znajomych lub obcych, trzeba zaprosić przynajmniej 18 gości).

Metoda wyłuskiwania
Wspomniane wyżej ścisłe twierdzenia w zaskakujący sposób odwracają logikę poszukiwania prawidłowości. Matematyka głosi: powiedz mi, jaki wzorzec chciałbyś dostać, a powiem ci, jak duża musi być twoja baza danych, żebyś znalazł go tam z pewnością! Konfuzję wzmaga fakt, że nie wiemy, jak konkretnie szukana prawidłowość się zrealizuje, więc może nam się wydać zaskakujące, kiedy już ją zobaczymy.
Można zatem wysunąć następującą tezę: przytłaczająca większość prawidłowości, które „odkrywamy” w wielkich bazach danych, jest pozorna lub wręcz fałszywa. To znaczy – są one związane tylko i wyłącznie z wielkością próbki i nie mówią nam nic o zjawiskach, których dane dotyczą. Owe miraże biorą się z samych wartości liczbowych, zupełnie ignorując etykietki. Dlatego nie ma znaczenia, czy baza danych dotyczy fizyki, biologii, psychologii czy historii.
Algorytmy autorstwa specjalistów od data science mogą być bardzo pomocne (a często są wręcz konieczne!) podczas analizy danych eksperymentalnych. Jednak opieranie się na samych danych jest równie groźne jak bezkrytyczne zawierzenie czystej teorii. Dzięki wielu wiekom interakcji zarówno matematyka, jak i filozofia nauki oferują nam szereg narzędzi i kryteriów pozwalających wyłuskać te wzorce, które rzeczywiście odzwierciedlają jakiś aspekt otaczającego nas świata.
Parafrazując słynny passus z „Rejsu” w reżyserii Marka Piwowskiego, można zapytać: świetnie, ale jaką metodą wybierzemy metodę wyłuskiwania? Na to pytanie nie ma jednoznacznej odpowiedzi, a o tym, że być jej nie może, również mówi nam matematyka, a dokładnie tzw. twierdzenia limitacyjne w systemach formalnych. Ale to już temat na odrębne rozważania. ©
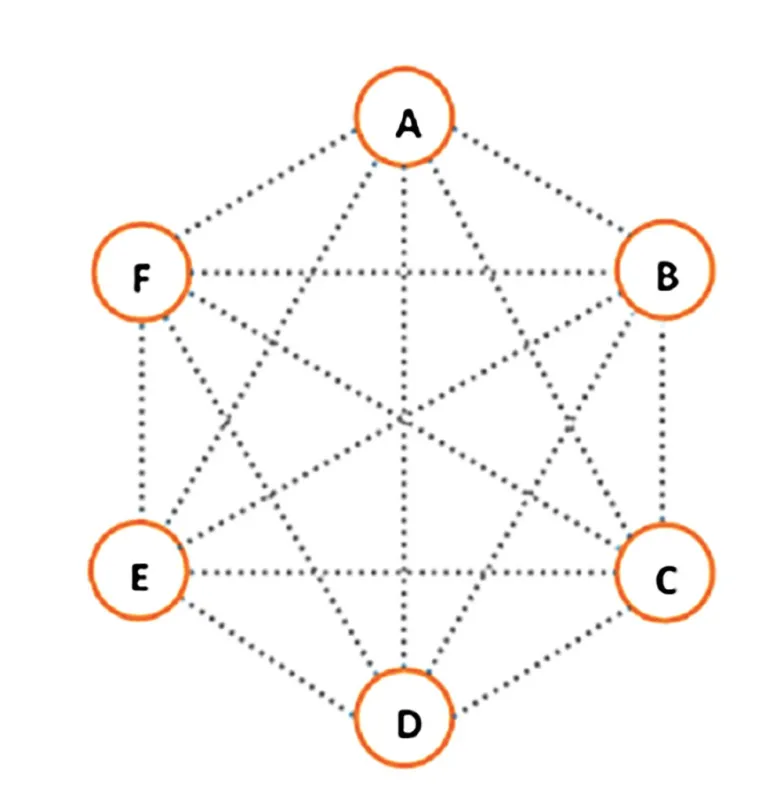
PROBLEM TOWARZYSTWA
Na przyjęciu bawiło się 6 osób: Alicja, Bogdan, Czarek, Dawid, Ewa i Franek. Linie łączące odpowiednie litery określają wzajemne relacje danej pary. Jeśli osoby się znają, rysujemy niebieską kreskę, a jeśli nie, to czerwoną. Ponieważ z każdego wierzchołka wychodzi 5 linii, przynajmniej 3 z nich muszą być tego samego koloru. A z tego wynika, że przy sześciu wierzchołkach zawsze powstanie przynajmniej jeden jednokolorowy trójkąt. A zatem, jakiekolwiek bybyły wzajemne relacje uczestników, to zawsze istnieje trójka osób znających się nawzajem albo będących sobie obcymi.
„Tygodnik Powszechny” – jedyny polski tygodnik społeczno-kulturalny.
30 tys. Czytelniczek i Czytelników. Najlepsze Autorki i najlepsi Autorzy.
Wspólnota, która myśli samodzielnie.


Artykuł pochodzi z numeru Nr 34/2019

")





