/ Fot. Domena publiczna / Sebastian J. Szybka / montaż „TP”")
Matematyka, będąc językiem, może być użyta nie tylko do informowania, ale między innymi, aby uwodzić.
Benoît Mandelbrot, „Fractals: Form, Chance and Dimension”, 1977
Słownik PWN definiuje „chaos” jako stan bezładu, całkowity brak porządku. W publikacjach naukowych słowo to ma obecnie inne znaczenie. Co prawda ciągle kojarzy się ono z bałaganem i brakiem przewidywalności, lecz w tle zawsze pojawia się struktura nadrzędna – to, co jest nieuporządkowane z bliska, oglądane z szerszej perspektywy staje się uporządkowane i piękne.
Tak rozumiany chaos można scharakteryzować za pomocą dwóch określeń: jest on nieprzewidywalny, a zarazem deterministyczny. Te dwa przymiotniki zdają się sobie przeczyć. To między innymi dlatego ta arcyciekawa i fundamentalna cecha świata przez setki lat pozostawała niezauważona.
Czym jest więc chaos deterministyczny i czym ten cudownie uporządkowany uwodzicielski bałagan różni się od prawdziwego bezładu? Aby to zrozumieć, posłużmy się przykładem.
Prosty przepis na wielki bałagan
Wyobraźmy sobie biegacza, który przygotowuje się do zawodów. Każdego wieczoru upublicznia on informację o dystansie pokonanym danego dnia, ale plan jego przyszłych treningów okryty jest tajemnicą. Czy znajomość dotychczasowych zwyczajów pozwoli nam odgadnąć jego plany na przyszłość? Liczba kilometrów pokonywanych przez biegacza każdego dnia nie jest większa od, powiedzmy, 18 km i tworzy ciąg liczb, który wydaje się przypadkowy. Może więc plan treningowy jest losowy?
Zaryzykujmy pierwszą, być może naiwną hipotezę: każdego dnia rano sportowiec trzykrotnie rzuca kostką i przebiega tyle kilometrów, ile łącznie wypadnie oczek. Taką zabawę określamy mianem procesu stochastycznego. Analizując dotychczasową aktywność sportowca (np. rozrzut przebywanych odległości i ich wartość średnią), można podjąć próbę weryfikacji naszej hipotezy. Jeśli okaże się ona prawdziwa, to nie można przewidzieć dystansu, jaki przebiegnie biegacz następnego dnia, ale można określić prawdopodobieństwo danego wyniku. Seria rzutów kostką nie jest procesem deterministycznym. Jest to proces losowy. Odległość, którą przebiegnie biegacz jutro, nie zależy od tego, ile przebiegł dzisiaj, ani od historii jego treningów.
Nauka zna wiele przykładów zjawisk, które należy opisywać właśnie w podobny sposób – jako procesy stochastyczne. Procesy takie opierają się na zjawiskach losowych. Ta losowość może mieć charakter fundamentalny, który nie wynika z niekompletności modelu czy też teorii (np. rozpad promieniotwórczy opisywany w ramach mechaniki kwantowej), lub być wynikiem złożoności i niemożności dokładnego opisania systemu (tak jak rzut kostką). Istnieje cały aparat matematyczny, który umożliwia zrozumienie właściwości procesów stochastycznych, a jednym z pionierów badań tego zagadnienia, obok Alberta Einsteina, był krakowski fizyk Marian Smoluchowski.
Powróćmy jednak do naszego sportowca. Wyobraźmy sobie, że hipoteza o rzutach kostką okazała się fałszywa: pojawiły się pewne przesłanki świadczące o istnieniu prostej reguły. Najprostszy nietrywialny plan mógłby być np. taki: każdego dnia, wraz ze wzrostem formy, biegacz przebiega trochę więcej.
Niech dn oznacza dystans pokonywany n-tego dnia. Załóżmy, że dystans przebywany dnia następnego (dn+1) spełnia równanie dn+1 = r × dn, gdzie r jest pewną stałą. Inaczej mówiąc, każdego dnia przemnażamy dystans z poprzedniego dnia przez tę samą liczbę r. Jeśli liczba ta będzie większa od 1 i jeśli pierwszego dnia biegacz trenował chociaż trochę, to przebiegany przez niego dystans będzie codziennie wzrastał. Znając odległość pokonaną podczas pierwszego treningu (d1), z łatwością można wyznaczyć plan na dowolny dzień, rozwiązując nasze równanie.
Niestety, jest to zbyt prosty schemat, by mógł być dla nas użyteczny. Przebiegany dystans nie powinien rosnąć w nieskończoność, a odległości pokonywane każdego dnia powinny sprawiać wrażenie przypadkowych.
Czy w ogóle istnieje prosta reguła, która równocześnie spełniałaby te dwa warunki?
Na początek spróbujmy uwzględnić fakt, że maksymalny przebiegany dystans to 18 km. Po ciężkim treningu należy się odpoczynek, więc do równania dodamy człon, który nam to zapewni. Jedna z najprostszych możliwości ma postać dn+1 = r × dn × (1 – dn/18 km). Jest to równanie, które może wyglądać na złożone, ale w istocie jest bardzo podobne do poprzedniego i różni się od niego tylko członem w nawiasie – to dzięki niemu dystans czasami może się też zmniejszać. Można wykazać, że jeśli pod r podstawimy dodatnią liczbę mniejszą lub równą 4, to odległość wskazywana przez nowy wzór nigdy nie przekroczy 18 km.
Tym razem, inaczej niż w przypadku poprzedniego równania, tylko dla kilku wartości r istnieją ścisłe rozwiązania umożliwiające wyliczenie dystansu przebieganego dowolnego dnia bez obliczania wszystkich wcześniej pokonywanych dystansów. W ogólnym przypadku, żeby wyliczyć, ile kilometrów pokona biegacz, powiedzmy, setnego dnia, należy pracowicie po kolei wyznaczać, jedna po drugiej, wszystkie odległości pokonane przez niego w ciągu poprzednich 99 dni.
Możemy wypróbować nowy wzór, sprawdzając, jak plan treningów na najbliższy rok zależy od wyboru stałej r. Zakładamy, że biegacz pierwszego dnia przebiegł 5 km (czyli d1=5km). Wykres będzie bardziej przejrzysty, jeśli przedstawimy tylko dwa ostatnie tygodnie pierwszego roku treningów.
Na przykład obliczenia pokazują, że dla r=2 po pierwszym tygodniu zmiennego treningu biegacz powinien przebiegać codziennie 9 km. Jeśli r=3,2, to po 10 dniach zmiennego treningu biegacz powinien pokonywać na przemian trochę ponad 14 km i trochę ponad 9 km. Gdy stała r ma wartość bliską 4, to długości tras wyglądają na przypadkowe. Świadczy o tym nieuporządkowane rozrzucenie punktów z prawej strony wykresu. Przykładowo, dla r=4, po zaokrągleniu do pełnych kilometrów, drugiemu i trzeciemu tygodniowi treningów odpowiada ciąg odległości: 16, 8, 18, 1, 2, 8, 18, 1, 3, 9, 18, 0, 0, 0 km.
Nie ma wątpliwości, że wzór, którego używamy, jednoznacznie determinuje ciąg pozornie przypadkowych liczb. W przeciwieństwie do sytuacji, w której o długości treningu decyduje rzut kostką, ten bałagan nie jest losowy, ale deterministyczny. Jest coś niezwykłego w tym, że tak skomplikowana sekwencja liczb została zakodowana w tak prostym wzorze.
To jednak nie koniec niespodzianek. Najciekawsze dopiero przed nami.
Chaos zwycięża komputery
Wyobraźmy sobie, że za pomocą naszego wzoru potrafimy odtworzyć pierwszy miesiąc treningów.
Obliczenia prowadzimy na kalkulatorze, który wyświetla maksymalnie 10 cyfr. W kolejnych krokach obliczeń zawsze podstawiamy pełny wynik, ale na kartce dla wygody zapisujemy wynik przybliżony za pomocą liczb całkowitych. Tak otrzymany ciąg liczb porównujemy z informacją podawaną przez biegacza, który tak samo zaokrągla wyniki (z wyjątkiem pierwszego dnia, kiedy podał wynik bardzo dokładnie). Poprawność miesięcznych przewidywań upewnia nas o słuszności odgadniętego wzoru. Niespodziewanie pierwszego dnia kolejnego miesiąca (32. dzień treningów) biegacz ogłasza, że pokonał dystans 2 km, podczas gdy nasze obliczenia przewidują 3 km. Przez trzy kolejne dni nasze przewidywania są znowu trafne, lecz potem zgodność zostaje całkowicie utracona. Wzór przestał działać. Jak to możliwe?
Zachęcam do samodzielnego sprawdzenia wyniku. Rezultat takiego zbiorowego eksperymentu byłby zaskakujący. Początkowo przewidywania nas wszystkich byłyby zgodne i plan treningu na miesiąc, a może nawet trochę dłużej, dałoby się odgadnąć. Po tym czasie obliczenia całkowicie przestałyby się zgadzać. Co dziwniejsze, wyniki zależałyby od modelu użytego kalkulatora lub komputera, a nawet od samego sposobu zapisu wzoru i kolejności wykonywanych operacji. Jeśli biegacz, planując treningi, używał naszego wzoru i korzystał z kalkulatora, to jego plan po pewnym czasie również stanie się niezgodny z „prawdziwym” planem ukrytym w strukturze naszego prostego równania. Jest tak, jak zapowiadałem. Chaos, chociaż deterministyczny, okazał się nieprzewidywalny.
W celu wyjaśnienia tej zagadki rozważmy kolejny matematyczny eksperyment. Jak zmieniłby się plan treningów, gdyby zamiast równych 5 km sportowiec pierwszego dnia przebiegł 5 km i 10 cm? Te 10 cm wydaje się bez znaczenia. To nie jest nawet połowa długości buta. A jednak okazuje się, że nowy plan uwzględniający dodatkowe 10 cm już po dwóch tygodniach będzie się całkowicie różnił od poprzedniego. Nasz wzór, który generuje chaos, ma ciekawą własność zwaną wrażliwością na warunki początkowe – drobne różnice w obliczeniach bardzo szybko narastają. Właśnie dlatego obliczenia o skończonej dokładności po stosunkowo małej liczbie kroków będą dawały odmienne wyniki zależne od użytego narzędzia. Pozornie nieistotne, pojawiające się na najdalszych miejscach po przecinku różnice w zaokrąglaniu liczb dosyć szybko dają o sobie znać. Bez względu na to, czy korzystamy ze starego kalkulatora, czy z wartego miliardy superkomputera, możliwość przewidywania wcześniej czy później się załamie.
Czy nie ma jednak sposobu, aby pokonać chaos? W odróżnieniu od procesów stochastycznych (na przykład rzutów kostką) krótkoterminowe przewidywania dla układów chaotycznych mogą być bardzo precyzyjne. Jeśli obliczenia będziemy prowadzić ręcznie, wykorzystując kartkę i ołówek (albo programy komputerowe, które potrafią operować ułamkami, nie zamieniając ich na liczby o skończonej dokładności), i jeśli dystans pokonany pierwszego dnia będzie zadany przez liczbę wymierną (taką, którą da się zapisać w postaci ułamka dwóch liczb całkowitych), to wynik uzyskany w każdym kroku będzie również liczbą wymierną. Będzie to wynik dokładny, bez żadnych przybliżeń. Obliczenia prowadzone w ten sposób możemy kontynuować dowolnie długo, ale nie jest to metoda bardzo efektywna: już w 29. dniu do zapisania wyniku w pełnej postaci trzeba wykorzystać ponad pół miliarda cyfr. Czas potrzebny do ręcznego zapisania takich liczb na papierze (pomijając czas niezbędny na obliczenia) przekracza czas życia pojedynczego człowieka. Nawet dla współczesnych komputerów przeprowadzenie tego typu obliczeń nie jest zadaniem łatwym (mój domowy komputer po osiągnięciu 29. dnia odmówił dalszej współpracy).
Podejmijmy jeszcze jedną próbę pokonania chaosu. Nasz wzór dla r=4 posiada ścisłe rozwiązanie, tzn. dystans przebiegnięty dowolnego dnia można wyznaczyć w jednym kroku po prostu na podstawie długości treningu w pierwszym dniu, bez żmudnego wyliczania wszystkich odległości. Jest to bardzo niezwykła cecha, bo dla pozostałych wartości r, dla których pojawia się chaos, ścisłe rozwiązanie nie istnieje. Możliwość użycia tego rozwiązania znacznie zwiększa naszą efektywność w wyznaczaniu planu treningów. Dla niektórych wartości d1 możemy przewidywać plan treningowy na dowolną liczbę lat (takie rozwiązania nie są chaotyczne, lecz periodyczne). Dla pozostałych wartości d1 w ścisłym rozwiązaniu pojawiają się liczby niewymierne i jeśli chcemy poznać dokładny wynik, to znowu jesteśmy skazani na obliczenia numeryczne (chociaż tym razem o wiele mniej żmudne), a co za tym idzie: nasze zdolności przewidywania są ograniczone.
Dla fizyka źródło problemu leży jednak gdzie indziej. Liczbę kilometrów przebytych pierwszego dnia znamy na podstawie pomiaru, a dokładność każdego pomiaru jest ograniczona. Jeśli, mierząc ten dystans, pomylimy się nawet o milimetr (to jest naprawdę niewiele przy odległości 5 km), to nasz wzór sprawi, iż ta pomyłka po pewnym czasie całkowicie zmieni plan treningów. Możliwość wyznaczania wyniku na wiele dni naprzód nic tu nie pomoże, bo nie potrafimy wyeliminować błędu ukrytego w samym pomiarze.
Obiecałem Czytelnikom determinizm bez przewidywalności i dotrzymałem słowa. Obiecałem też ukryty porządek i piękno. Opowiem o nich, umieszczając nasz przykład w szerszym kontekście.
Piękno i porządek
Rozważany przez nas wzór nosi nazwę odwzorowania logistycznego. Jest to jeden z najprostszych przykładów odwzorowań chaotycznych. Wśród pionierów badań tego odwzorowania można wymienić polskiego matematyka ze szkoły lwowskiej, Stanisława Ulama, który w trakcie prac w ramach Projektu Manhattan próbował wykorzystać własności odwzorowania logistycznego do stworzenia generatora liczb losowych dla pierwszego na świecie komputera (ENIAC). Samo równanie w sposób bardzo naturalny pojawia się w biologii w modelach wzrostu populacji. Odwzorowanie logistyczne to szczególny przypadek tzw. odwzorowań rekurencyjnych, czyli takich, które w wyniku iteracji definiują ciąg liczb. W matematyce istnieje wiele innych typów równań, a chaos może pojawić się praktycznie we wszystkich z nich.
Piękno i porządek zawarte w chaosie najłatwiej uwidocznić, wykorzystując fraktale, czyli struktury geometryczne pojawiające się wszędzie tam, gdzie pojawia się chaos. Skoro mowa o pięknie, to odwołajmy się do sztuki. Z matematycznego punktu widzenia rzeźbiarze tworzą dwuwymiarowe struktury zanurzone w trójwymiarowej przestrzeni. Malarze wykorzystują dwuwymiarowe powierzchnie, aby za pomocą śladów pędzla (jednowymiarowe krzywe) i plam tworzyć swoje dzieła. Niewielu artystom, wyjątkiem jest na pewno Salvador Dalí i jego „Crucifixion (Corpus Hypercubus)”, udało się wyłamać z tych przestrzennych przyzwyczajeń. Niewątpliwie nasz mózg w toku ewolucji najlepiej przystosował się do podziwiania piękna w dwóch lub trzech wymiarach.
Natura nie zna takich ograniczeń. Być może czytelników nie zachwyci dzieło sztuki, które zawiera w sobie odwzorowanie logistyczne – zanurzone jest ono w jednym wymiarze.
Spójrzmy wobec tego na przykład bardziej zbliżony do naszych malarskich upodobań. Rozważmy bardzo proste odwzorowanie zn+1 = zn2 + z0, które operuje na tzw. liczbach zespolonych. Nie wdając się w szczegóły: każda liczba zespolona odpowiada punktowi na płaszczyźnie, a samo odwzorowanie wyróżnia pewien zbiór punktów C, który śmiało można nazwać dziełem sztuki. Zbiór C został odkryty w 1979 r. przez urodzonego w Warszawie francuskiego matematyka Benoîta Mandelbrota. Na ilustracjach poniżej widać fragment tego zbioru.

Chaos wokół nas
Chaos deterministyczny nie jest wyłącznie ciekawostką matematyczną. W opisie układów fizycznych pojawia się on powszechnie. Choć może nie wszyscy zdają sobie z tego sprawę, to spotykamy się z nim na co dzień, np. gdy dolewamy mleka do ciepłej kawy. Nie potrafimy wiarygodnie przewidywać pogody na dłużej niż kilka dni, bo jak zauważył matematyk i meteorolog Edward Lorenz, ruch skrzydeł motyla w Brazylii może wywołać tornado w Teksasie. Chaos pojawia się również w Układzie Słonecznym. Mieszkając na jednym z czterech mniejszych księżyców Plutona, mielibyśmy okazję podziwiać chaotyczne zachody Słońca. Nawet ruch Ziemi i innych planet rozpatrywany w bardzo długiej skali czasu podlega prawom nieprzewidywalności chaosu.
Parę lat temu wraz z profesorem Tadeuszem Chmajem badaliśmy, w ramach teorii grawitacji Einsteina, możliwość utworzenia miniaturowych czarnych dziur za pomocą specjalnie dobranych fal grawitacyjnych. Odkryliśmy, iż pusta przestrzeń i czas mogą wibrować chaotycznie. Ruch skrzydeł motyla może wywołać tornado, ale może też wpłynąć na proces formowania się czarnych dziur!
Piękno chaosu deterministycznego przejawia się nie tylko w fantazyjnej i nieskończenie skomplikowanej strukturze związanych z nim fraktali. Bardzo proste równania, zapisane za pomocą szkolnej matematyki, kryją w sobie bogactwo, które ilustruje głęboką prawdę o otaczającym nas świecie. Prawda ta, będąc w zasięgu ludzkich umysłów, pozostawała niedostrzeżona przez setki lat. Jej odkrycie wniosło do naszego rozumienia determinizmu więcej niż wszystkie dysputy prowadzone na ten temat od czasów Newtona.
Determinizm nie oznacza przewidywalności. Myślę, że Newton, Laplace i inni wielcy minionych wieków byliby tym faktem zaskoczeni, ale i głęboko oczarowani. ©
Autor jest doktorem habilitowanym, pracuje na Uniwersytecie Jagiellońskim w Zakładzie Astrofizyki Relatywistycznej i Kosmologii (Obserwatorium Astronomiczne). Specjalizuje się w teorii grawitacji Einsteina. Jego zainteresowania naukowe dotyczą czarnych dziur, fal grawitacyjnych i kosmologii.
Obliczenia i diagram wykonano w systemie algebry komputerowej Wolfram Mathematica.
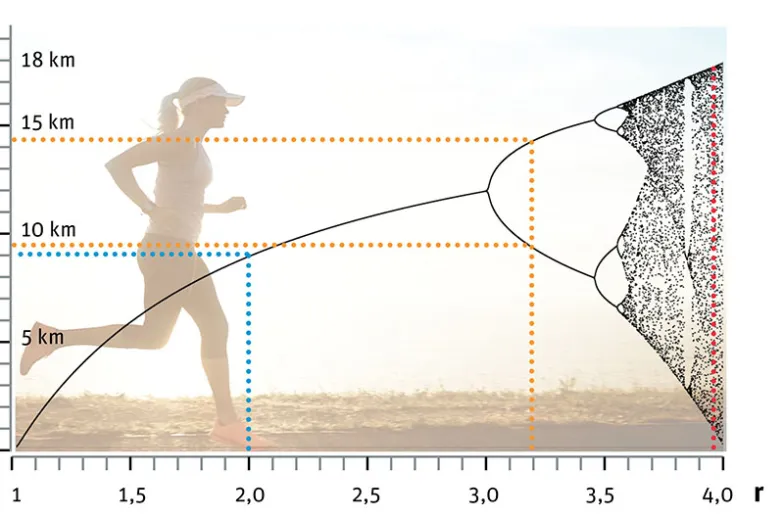
Opis wykresu:
Oś pionowa: długości tras przypadające na dwa ostatnie tygodnie pierwszego roku treningu w zależności od wyboru stałej r. Oś pozioma: wielkość stałej r, zakres 1,0 – 4,0.
Dla r=2 nasz wzór pokazuje, że biegacz przez ostatnie dwa tygodnie pierwszego roku treningów powinien pokonywać codziennie taki sam dystans 9 km (dlatego 14 czarnych punktów odpowiadających dwóm tygodniom treningów nakłada się na siebie).
Dla r=3,2 nasz wzór przewiduje, że biegacz pokonywać będzie naprzemiennie trochę ponad 9 km i trochę ponad 14 km (14 punktów rozdziela się na dwie grupy, stąd nad r=3,2 widzimy dwa punkty).
Plan treningów jest naprawdę interesujący, gdy r jest bliskie 4 (14 punktów rozbiega się w sposób pozornie przypadkowy). Stąd czarne punkty są „rozsypane” chaotycznie po prawej stronie rysunku.
Zobacz także:
- Darmowe oprogramowanie umożliwiające wizualizację trójwymiarowych fraktali: www.mandelbulber.com
- Fraktale na usługach sztuki: vimeo.com/juliushorsthuis
„Tygodnik Powszechny” – jedyny polski tygodnik społeczno-kulturalny.
30 tys. Czytelniczek i Czytelników. Najlepsze Autorki i najlepsi Autorzy.
Wspólnota, która myśli samodzielnie.


Artykuł pochodzi z numeru TP 48/2016

Artykuł pochodzi z dodatku Wielkie Pytania #3: Porządek i chaos